안녕하세요. Google 프로그래머인 Cassandra Shaw입니다.
Google 내 다른 그룹의 TensorFlow 사용을 돕고 있죠.
이 섹션에서는 손실 줄이기를 다룰 건데요,
지난 시간에는 손실을 계산하는 법을 알아봤죠.
그럼 손실을 최소화하는 매개변수는 어떻게 찾아낼까요?
매개변수 공간 안에 나아갈 방향이 있으면 좋겠죠.
초매개변수 세트를 새로 적용할 때마다 손실이 줄어드는 방향으로요.

이때 방향을 잡기 위해서 경사를 계산해 볼 수 있어요.
모델 매개변수를 감안한 손실 함수의 도함수인 거죠.
제곱 손실처럼 간단한 손실 함수의 도함수는 계산하기 쉬워요.
모델 매개변수를 효율적으로 업데이트할 수도 있고요.

이때 반복적인 접근방식을 사용하는데요,
입력된 데이터를 기반으로 손실 함수의 경사를 계산해요.
경사가 음수면 그쪽 방향으로 모델 매개변수를 업데이트하죠.
그 방향으로 나아가면서 손실을 줄이는 거예요.
그런 다음 모델을 업데이트하고 경사를 다시 계산하기를 반복하죠.

1차원이라고 가정하면 손실 함수는 이런 모양이에요.
단일 모델 매개변수의 θ를 손실에 매핑하게 되죠
임의의 값을 초기 θ 값으로 잡으면 해당하는 손실을 구할 수 있어요.
그런 다음 음의 경사를 계산하면
어떤 방향으로 가야 손실이 줄어들지 알게 되죠.
경사 방향으로 이동하면 새로운 손실을 얻을 수 있어요.
이렇게 경사 방향으로 가다 보면 극솟값을 지나게 돼요.
이 값에서 음의 경사를 구하면 왔던 방향으로 돌아가게 되죠.
그러면 음의 경사 방향으로 한 번에 얼마씩 이동해야 할까요?
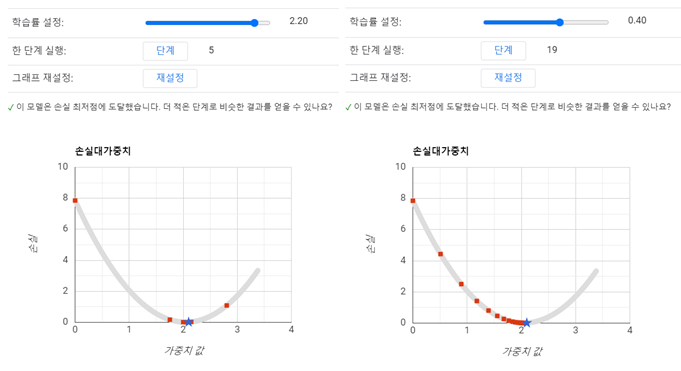
그건 학습률에 따라 달라요.
설정할 수 있는 초매개변수죠.
학습률이 아주 작으면
작은 보폭으로 여러 번 이동해서 계산을 여러 번 해야 극솟값에 도달할 수 있어요.
반면에 학습률이 크면
더 큰 보폭으로 이동하게 되고 극솟값보다 더 멀리 갈 수도 있죠.
손실이 더 커지는 지점에 다다를 수도 있고요.
높은 차원의 모델에서는 발산이 발생할 수도 있습니다.
이런 경우가 발생하면 학습률의 자릿수를 줄여야 해요.
지금까지 경사하강법이라는 알고리즘을 살펴보았는데요.
한 지점에서 출발해 극솟값에 닿길 바라며 점점 이동해 가는 거죠.
그런데 이때 출발점이 중요할까요?
잠깐 생각해보죠.
미적분 시간에 우리는 커다란 그릇처럼 생긴 볼록함수를 배웠어요.
이 그릇의 어딘가에서 출발해서 적당한 보폭으로 경사를 따라가면 결국 그릇 바닥에 이르게 되겠죠.

하지만 머신 러닝 문제는 볼록함수가 아닐 때가 많아요.
특히 신경망은 모양이 볼록하지 않기로 유명하죠.
사실 신경망은 그릇 모양이 아니라 계란판처럼 생겼어요.
극솟값이 여러 개 있는데
그중에 유용한 값도 있고 아닌 것도 있어요.
그래서 초깃값이 중요하다는 거예요.
이 문제는 나중에 다루죠.
잠깐 효율성에 관해 생각해 볼게요.

손실 함수에서 경사를 계산할 때
수학적인 방식을 사용하면 데이터 세트 안에 있는 모든 예시의 경사를 구해야 하죠.
그래야만 제대로 된 경사 방향을 따라갈 수 있으니까요.
하지만 예시가 백만 개나 십억 개가 넘어가는 대규모 데이터 세트에서는
이동할 때마다 계산을 아주 많이 해야 하죠.
하지만 전체 데이터 세트가 아니라
하나의 예시에서만 손실의 경사를 계산해도 대체로 괜찮다는 것이 경험적으로 입증되었어요.
이 방법을 쓰면 더 큰 보폭으로 이동해야 하지만
해결책에 도달하는 데 드는 전체 계산량은 훨씬 적어지죠.
이러한 방법을 확률적 경사하강법이라고 해요.
실무에서는 이 둘의 중간쯤에 있는 방법을 사용해요.
하나의 예시 또는 전체 데이터 세트가 아닌
10개에서 1,000개 정도의 예시가 포함된 배치를 사용하는 거죠.
이를 미니 배치 경사하강법이라고 하고요.